Abstract
BPR主要用于基于隐式反馈(implicit feedback)的Item Recommendation。
尽管有很多做同样事情的算法比如matrix factorization, knearest-neighbor。但他们并不是直接对于物品排名本身进行预测的。
而BPR则是通过贝叶斯分析得到最大的后验估计量来预测排名。
我的理解就是,MF,KNN算法是预测出用户对每个item的感兴趣程度,然后排名,而BPR则是通过预测用户对A的兴趣大于B的概率,从而预测排名。
Bayesian Personalized Ranking
$y_{ui} = 1$,if interaction (user u, item i) is observed
$y_{ui} = 0$,otherwise
在传统隐式反馈模型中,如果用户 $u$ 和物品 $i$ 的交互没有被观测到(数据缺失),那么就会被归为负类。那么如果这个模型训练的足够好,那么所有未被观测到的样本,随后都会被预测为 0。
而使用BPR就是为了解决这类问题。
后验概率
构建一个数据集 $D_s$,如果用户 $u$ 对物品 $i$ 产生了交互而没有对物品 $j$ 产生交互,则会得到一个偏好对 $(u,i,j)$。即 $D_s = {(u,i,j) | i\in I_u^+ \land I\setminus I_u^+}$(可以理解为同时有物品 $i,j$ 的时候,用户 $u$ 点击了 $i$)。
定义 $p(i >_u j|\theta)$ 为用户 $u$ 有 $\theta$ 的概率有偏好对 $(u,i,j)$。
那么我们的任务就是求 $\theta$,即根据数据集(用户对物品的偏序关系 $>_u$)。
而
求 $p(>_u|\theta)$
这就相当于,我们知道了每一对的 $i >_u j$ 偏序概率。
那么总的概率就是把它们相乘即可:
我们可以用相关性来定义 $p$,即 $p(i >_u j) = \sigma(\hat{x}_{u,i,j}(\theta))$
- $\sigma$ 为sigmoid函数,$\sigma(x) = \frac{1}{1+e^{-x}}$
- $\hat{x}_{u,i,j}(\theta)$ 是实值函数,返回用户 $u$ 与物品 $i,j$ 之间的关系,可以用矩阵分解或KNN得到。
求 $p(\theta)$
假设参数服从正态分布 $p(\theta) \sim N(0, \lambda_0 I)$。
求后验概率
梯度下降
可以采用随机梯度下降,其中 $x_{uij} = x_{ui} - x_{uj}$。
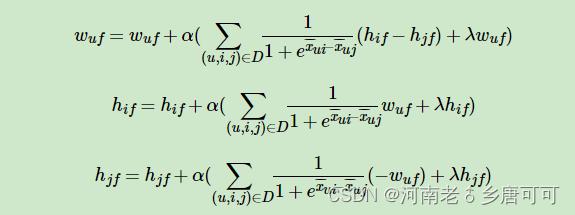
参考博客
https://blog.csdn.net/weixin\_46099084/article/details/109011670
https://zhuanlan.zhihu.com/p/60704781
https://www.cnblogs.com/pinard/p/9128682.html#commentform



![[ZJOI2010]数字计数 解题思路](/medias/featureimages/10.jpg)