Abstract
因式分解机(Factorization Machines)是一种结合了支持向量机(Support Vector Machines, SVM)的模型。与SVM不同的是,FM 使用对变量之间的所有交互进行建模。所以在数据特别稀疏的情况下,FM也能准确度较高地预测。
此外,FM的计算时间复杂度是线性的。以及通过对输入数据格式的调整,FM可以模仿其它的算法,比如SVD++, PITF等。
支持向量机(Support Vector Machines, SVM)
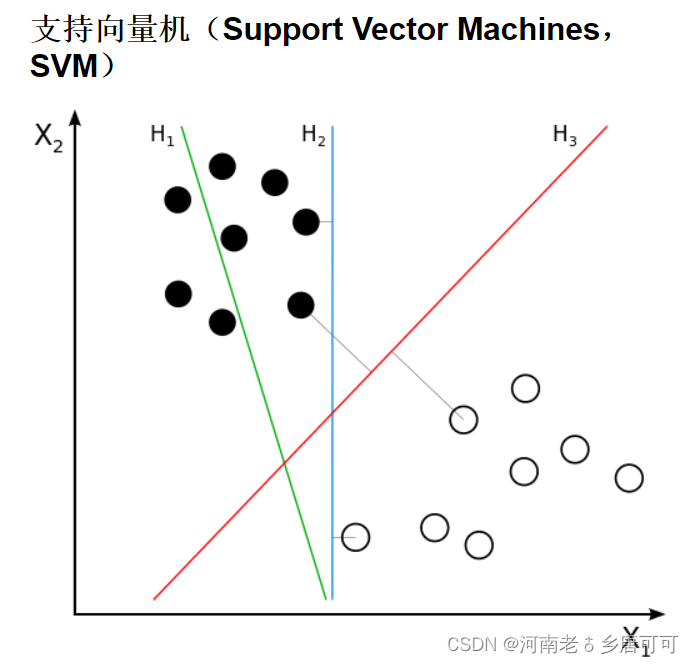
可以理解为是一种二类分类器。
可以参考https://zhuanlan.zhihu.com/p/49331510
I. INTRODUCTION
在类似协同过滤的模型中,标准SVM预测器在这些任务中不成功的唯一原因是它们无法在非常稀疏的数据下在复杂(非线性)内核空间中学习可靠的参数。
- 它们不适用于标准预测数据(例如 Rn 中的实值特征向量。)
- 很多相关模型都是根据特定的数据集而专门构造的。
而,FM是一种通用的预测器,可以处理任何实值特征向量。 与此相反,其他最先进的分解模型仅适用于非常有限的输入数据。通过调整输入数据的特征向量,FM就可以模仿其它的推荐系统。
II. Factorization Machine
假设特征向量为 $x = (x_1, x_2, …, x_n)$,传统的预测方式是:
即初值加上每个特征带来的权值和。
但是这样会错过一些有重要意义的特征组合。
比如:抽烟,酗酒都会对身体造成危害,可以按照权重来分别累加。但是同时抽烟酗酒带来的危害肯定比单独抽烟、酗酒加起来要多。
所以应该再加上同时抽烟酗酒带来的危害。
那么加上组合的式子为:
那么就可以解决之前的那个问题,甚至可以加更高阶的组合。
但是这样又带来了一个新的问题,这样一来,训练的参数就更多了,达到了 $O(n^2)$ 级别。且在数据比较稀疏的情况下($w_i w_j$ 同时不为 0 的数量较小),就会导致参数训练不充分,严重影响预测精度。
$W_{n\times n}$ 是一个对称矩阵,可以将其分解为两个较小矩阵的乘积 $V_{n\times k} \cdot V^T$,即 $W = V \cdot V^T$。
通过调整 $k$ 的大小,可以调整训练参数数量,在数据比较稀疏的情况下,应该设置 $k << n$。
那么 $w_{ij} = \sum_{k=1}^{n} V_{ik} \cdot V_{kj}^T$,此时:



